第一章 单元测试
1、单选题:
SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。
选项:
A:剑桥大学
B:波士顿大学
C:哈佛大学
D:斯坦福大学
答案: 【斯坦福大学】
2、单选题:
()的功能是显示管理SPSS统计分析结果、报表及图形。
选项:
A:变量视图
B:数据编辑窗口
C:结果输出窗口
D:数据视图
答案: 【结果输出窗口】
3、单选题:
数据编辑窗口的主要功能有()
选项:
A:录入编辑和管理待分析的数据
B:结果输出
C:编辑统计图形
D:编辑程序语言
答案: 【录入编辑和管理待分析的数据】
4、单选题:
()是SPSS为用户提供的基本运行方式。
选项:
A:其余三项都是
B:程序运行方式
C:完全窗口菜单方式
D:混合运行方式
答案: 【其余三项都是】
5、单选题:
()文件格式是SPSS独有的。一般无法通过Word、Excel等其他软件打开。
选项:
A:flv
B:sav
C:mp4
D:txt
答案: 【sav】
6、多选题:
SPSS软件的常用窗口主要有()
选项:
A:语句窗口
B:图形编辑窗口
C:输出窗口
D:数据编辑窗口
答案: 【语句窗口;
图形编辑窗口;
输出窗口;
数据编辑窗口】
7、多选题:
数据编辑窗口叙述正确的是()
选项:
A:数据编辑区行向为变量,左侧显示变量名称
B:数据编辑区行向为观测,左侧为系统自动观测号
C:数据编辑区列向为观测,顶端为系统自动观测号
D:数据编辑区列向为变量,顶端显示变量名称
答案: 【数据编辑区行向为观测,左侧为系统自动观测号;
数据编辑区列向为变量,顶端显示变量名称】
8、多选题:
数据视图用于()
选项:
A:样本数据的修改
B:样本数据的查看
C:样本变量的定义
D:样本数据的录入
答案: 【样本数据的修改;
样本数据的查看;
样本数据的录入】
9、单选题:
可用于变量属性的输入和修改的窗口是()
选项:
A:图形编辑窗口
B:变量视图
C:数据视图
D:结果输出窗口
答案: 【变量视图】
10、多选题:
SPSS数据编辑窗口由()组成。
选项:
A:数据编辑区
B:工具栏
C:系统状态显示区
D:窗口主菜单
答案: 【数据编辑区;
工具栏;
系统状态显示区;
窗口主菜单】
第二章 单元测试
1、单选题:
下列变量名称是合法命名的是()
选项:
A:and
B:1a00
C:a001
D:a(01)
答案: 【a001】
2、多选题:
SPSS21中变量类型有()
选项:
A:受限数值型
B:数值型
C:字符型
D:日期型
答案: 【受限数值型;
数值型;
字符型;
日期型】
3、多选题:
SPSS中标签的含义正确的是()
选项:
A:变量标签是对变量取值含义的解释
B:变量值标签是对变量名称的解释
C:变量值标签是对变量取值含义的解释
D:变量标签是对变量名称的解释
答案: 【变量值标签是对变量取值含义的解释;
变量标签是对变量名称的解释】
4、多选题:
下列哪些情况有可能需要在SPSS变量属性中定义缺失值?()
选项:
A:学生成绩变量中,某些同学的成绩超过了满分100分
B:月收入变量中,某些样本的收入数据为空
C:性别变量中,0、1分别表示男、女。但数据中出现了数字3、6、9
D:月收入变量中,收入中位数为6500元,而最大值为10万元。
答案: 【学生成绩变量中,某些同学的成绩超过了满分100分;
性别变量中,0、1分别表示男、女。但数据中出现了数字3、6、9;
月收入变量中,收入中位数为6500元,而最大值为10万元。】
5、多选题:
下列哪些变量适合定义成定类型变量(名义)?()
选项:
A:收入
B:职业
C:满意度
D:性别
答案: 【职业;
性别】
6、多选题:
下列哪些变量适合定义成定序型变量(序号)?()
选项:
A:产品质量等级
B:民族
C:洗衣机销售额
D:教师专业技术职称
答案: 【产品质量等级;
教师专业技术职称】
7、多选题:
下列哪些变量适合定义成定距型变量(度量)?()
选项:
A:电视机品牌
B:籍贯
C:考试成绩(百分制)
D:大米销售量
答案: 【考试成绩(百分制);
大米销售量】
8、多选题:
在SPSS中导入固定分隔符格式文本,要求文本数据()
选项:
A:相同变量数值不必排列在相同列下
B:文本文件中必须有变量名称
C:不同变量数值之间以相同符号隔开
D:相同变量数值排列在相同列下
答案: 【相同变量数值不必排列在相同列下;
不同变量数值之间以相同符号隔开】
9、多选题:
在SPSS中导入固定列宽格式文本,要求文本数据()
选项:
A:不同变量值之间必须有空格
B:文本文件中不一定有变量名称
C:相同变量数值排列在相同列下
D:不同变量数值之间以相同符号隔开
答案: 【文本文件中不一定有变量名称;
相同变量数值排列在相同列下】
10、单选题:
需要利用“添加ODBC数据源”功能导入到SPSS的数据文件是()
选项:
A:SPSS数据文件
B:数据库文件
C:文本文件
D:Excel文件
答案: 【数据库文件】
第三章 单元测试
1、单选题:
在同一数据文件中,将变量A的属性复制给变量B,需要用到的菜单是()
选项:
A:【数据】→【复制数据属性】
B:【数据】→【定义变量属性】
C:【数据】→【转置】
D:【数据】→【标识重复个案】
答案: 【】
2、单选题:
将数据文件A的所有变量属性复制给数据文件B,需要用到的菜单是()
选项:
A:【数据】→【定义变量属性】
B:【数据】→【复制数据属性】
C:【数据】→【转置】
D:【数据】→【标识重复个案】
答案: 【】
3、单选题:
某个SPSS数据文件中存储了100家上市公司1-12月的月财务报表数据(1200个个案,每个企业有1-12月12个个案),利用()菜单功能可以最快地只保留6月份的财务数据。文件中的变量:公司名称、纳税人识别号码、月份(用1-12个数字表示)以及其他财务指标变量。
选项:
A:【数据】→【加权个案】
B:【数据】→【选择个案】
C:【数据】→【排序个案】
D:【数据】→【标识重复个案】
答案: 【】
4、单选题:
SPSS数据文件中多个个案为相同个案,可以使用()菜单实现删除重复个案。
选项:
A:【数据】→【标识重复个案】
B:【数据】→【选择个案】
C:【数据】→【加权个案】
D:【数据】→【排序个案】
答案: 【】
5、多选题:
利用【数据】→【加权个案】菜单对数据加权操作时,权变量可以是()
选项:
A:0
B:负数的数值型变量
C:带小数的数值型变量
D:正整数的数值型变量
答案: 【】
6、多选题:
将二手列联表数据录入SPSS中,应遵循以下原则()
选项:
A:变量个数为属性变量个数加1,1即单元格频数变量
B:个案个数为属性变量各取值交叉单元格的个数以及行列合计的个数
C:变量个数为属性变量个数
D:个案个数为属性变量各取值交叉单元格的个数
答案: 【】
7、单选题:
菜单【数据】→【拆分文件】的功能是()
选项:
A:对个案进行筛选
B:对个案进行分组统计
C:对变量进行分组统计
D:将文件拆分成多个独立文件
答案: 【】
8、多选题:
两个数据文件进行纵向合并(添加个案)时,应满足()
选项:
A:两个文件中相同变量的变量名称可以不同
B:两个文件中相同变量属性要一致
C:两个文件中的个案要对应相同
D:两个文件中不能有不同变量
答案: 【】
9、多选题:
两个数据文件进行横向合并(添加变量)时,应满足()
选项:
A:采用关键变量合并时,必须先对两个文件中的个案都按照关键变量进行升序排列。
B:采用关键变量合并时,关键变量的取值必须是唯一的,无重复值。
C:两个文件中,关键变量的属性要保持一致。
D:两个文件中的有相同的个案数,并且个案排列顺序一一对应时,可以直接合并。
答案: 【】
10、多选题:
下列关于数据排序正确的是()
选项:
A:可以了解缺失值
B:快速找到最大最小值
C:计算全距
D:快速发现异常值
答案: 【】
第四章 单元测试
1、多选题:
SPSS基本运算有():
选项:
A:数学运算
B:逻辑运算
C:关系运算
D:算术运算
答案: 【】
2、单选题:
符号“&”是()
选项:
A:关系运算符
B:逻辑或运算符
C:逻辑非运算符
D:逻辑与运算符
答案: 【
3、多选题:
“对个案内的值计数”菜单可以实现()
选项:
A:字符型数据相同值出现次数的统计
B:每个个案中不同变量内的相同值出现的次数统计
C:每个变量内的相同值出现的次数统计
D:某一特定范围内数据出现次数的统计
答案: 【】
4、多选题:
在SPSS数据文件中存储了A、B、C三个变量,根据分析需求,要把A、B、C三个变量加权(A权数:0.3,B权数:0.4,C权数:0.3)综合成新变量D。以下做法正确的是()
选项:
A:综合变量D表达式为:0.3A+0.4B+0.3C
B:综合变量D表达式为:(3*A+4*B+3*C)/10
C:综合变量D表达式为:0.3*A+0.4*B+0.3*C
D:需使用【转换】→【计算变量】菜单功能
答案: 【】
5、多选题:
可实现连续型数值数据分组功能的菜单是()
选项:
A:【转换】→【重新编码为相同变量】
B:【转换】→【自动重新编码】
C:【转换】→【重新编码为不同变量】
D:【转换】→【可视离散化】
答案: 【】
6、多选题:
在变量“服务满意度”中录入值为1、2、3、4、5,分别表示非常满意、满意、一般、不满意和非常不满意。如果计算平均分值时,“服务满意度”平均分越低表示越满意,这与通常认知不符。因此,需要对“服务满意度”取值调整,将原来录入的1、2、3、4、5对应改为5、4、3、2、1表示非常满意、满意、一般、不满意和非常不满意。下列哪些功能菜单可以实现?()
选项:
A:【转换】→【重新编码为不同变量】
B:【转换】→【自动重新编码】
C:【转换】→【可视离散化】
D:【转换】→【重新编码为相同变量】
答案: 【】
7、单选题:
对“季节性差分”函数说法正确的是()
选项:
A:产生原变量值序列的相邻值之间的变差。
B:将原变量序列的各项观测值按指定的阶数向前平移。
C:适用于具有季节性变动的时间序列,产生原时间序列相距一定周期值的观测量之间的变差。
D:将原变量值序列的观测值以指定的“移动项数”进行移动平均,产生时间序列。
答案: 【】
8、多选题:
搜集了某地区5年的服务业产值月度数据,其中第5年2月份的数据缺失。另外5年数据分布呈现线性上升趋势(无季节变动),那么在【转换】→【替换缺失值】菜单中,适用的缺失值替换方法是()
选项:
A:附近点的平均值
B:连续平均值
C:线性差值
D:点的线性趋势
答案: 【】
9、多选题:
在可视离散化操作中,如果选择“基于已扫描个案的平均和选定标准差处的分割点”进行分组,则以下叙述正确的是()
选项:
A:单独选择“+/-1标准差”选项,将产生“变量均值减1倍标准差”、“变量均值”和“变量均值加1倍标准差”3个分割点。
B:将“+/-1标准差”选项与“+/-2标准差”选项进行组合选择,将产生“变量均值减1倍标准差”、“变量均值减2倍标准差”、“变量均值”、“变量均值加1倍标准差”和“变量均值加2倍标准差”5个分割点。
C:单独选择“+/-3标准差”选项,将产生“变量均值减3倍标准差”、“变量均值”和“变量均值加3倍标准差”3个分割点。
D:单独选择“+/-2标准差”选项,将产生“变量均值减2倍标准差”、“变量均值”和“变量均值加2倍标准差”3个分割点。
答案: 【】
10、单选题:
用A、B、C三个已知变量加权求均值计算新变量D,其中A变量有个别个案为缺失值,则新变量D对应个案数值为()
选项:
A:B和C的加权平均值
B:用户缺失值
C:系统缺失值
D:0
答案: 【
第五章 单元测试
1、多选题:
适用于分类和顺序型数据的统计图形是()
选项:
A:条形图
B:箱线图
C:直方图
D:饼图
答案: 【】
2、多选题:
连续数值型数据可选用()
选项:
A:柱形图
B:直方图
C:饼图
D:茎叶图
答案: 】
3、多选题:
SPSS中的频数分布表包括的内容有()
选项:
A:累计百分比
B:有效百分比
C:百分比
D:频数
答案: 【】
4、多选题:
对于连续数值型数据编制频数分布表时,首先应该()
选项:
A:对数据进行可视离散化分组
B:对数据进行重编码分组
C:对数据直接编制频数分布表
D:对数据进行升序排列
答案: 【】
5、单选题:
有效百分比是各组频数占()的百分比。
选项:
A:缺失个案数
B:累积个案数
C:总个案数
D:有效个案数
答案: 【
6、多选题:
关于直方图与条形图叙述正确的是()
选项:
A:直方图适用于连续数值型数据分布展示
B:柱的高度都表示各组频数或频率
C:柱的宽度大小都不影响各组频数分布
D:条形图用于分类和顺序数据分布展示
答案: 【】
7、多选题:
不受数据极端值影响的描述统计量是()
选项:
A:中位数
B:分位数
C:均值
D:标准差
答案: 【】
8、多选题:
关于列联表分析,下列说法正确的是()
选项:
A:列联表分析是研究两个或更多属性变量(分类变量或顺序变量)之间是否存在关联性的方法。
B:检验统计量是卡方统计量
C:列联表包括频数表和频率表两类
D:检验零假设:各属性变量间无关联性(即相关性)
答案: 【】
9、多选题:
探索分析的作用是()
选项:
A:描述统计量的计算。
B:检查数据错误,查找异常值、影响值点或是错误输入的数据。
C:检查数据分布特征,检验正态分布,方差齐性检验。
D:制作分布图形,如直方图、茎叶图、正态概率Q-Q图和箱线图。
答案: 【】
10、多选题:
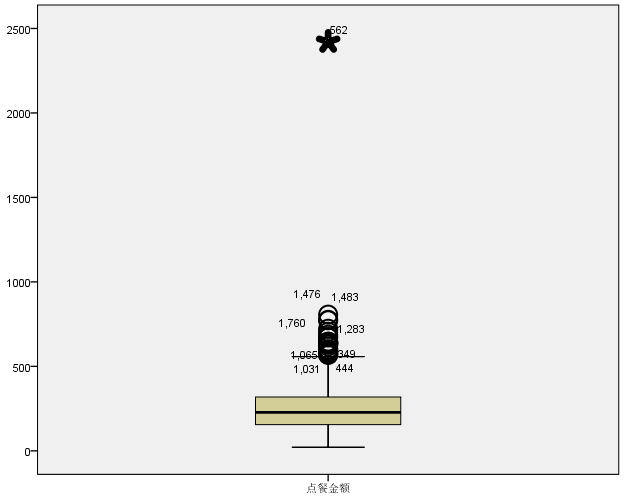 参照上图,关于箱线图下列说法正确的是( )
参照上图,关于箱线图下列说法正确的是( )
选项:
A:○代表极端值点,*代表影响值点
B:箱体下截止线为数据的最小值
C:箱体的上下宽度为数据的四分位差
D:箱体中间的实线为中位数的位置
答案: 【
第六章 单元测试
1、多选题:
在均值过程操作中,如果对“选项”选择默认操作,最终输出的统计量是()
选项:
A:个案数
B:标准差
C:均值
D:组中值
答案: 【】
2、多选题:
在独立样本T检验输出结果中,如果Levene检验结果不显著,则()
选项:
A:方差齐性,看方差不相等的检验结果。
B:方差齐性,看方差相等的检验结果。
C:方差非齐性,看方差不相等的检验结果。
D:方差非齐性,看方差相等的检验结果。
答案: 【】
3、单选题:
开发商在两个城市随机选取家庭进行收入调查,这里两个城市的家庭进行收入数据是()
选项:
A:单样本
B:相关样本
C:配对样本
D:独立样本
答案: 【
4、单选题:
为了检验某新药降低高血压的作用,随机挑选出一群患者,记录服药前和服药后的血压数据,这里服药前和服药后的血压数据是()
选项:
A:单样本
B:相关样本
C:独立样本
D:配对样本
答案: 【
5、单选题:
对于独立样本检验,数据特征是()
选项:
A:建立两个变量,分别存放两组变量
B:建立一个变量,为分组变量
C:建立一个变量,存放两组样本
D:建立两个变量,一个是分组变量,一个是对应样本值变量
答案: 【
6、单选题:
均值比较时,对于配对样本检验问题采用()
选项:
A:秩统计量
B:卡方统计量
C:t统计量
D:Z统计量
答案: 【
7、单选题:
均值比较中,单样本检验说法正确的是()
选项:
A:检验总体均值是否为0
B:P值大于0.05拒绝原假设
C:检验总体均值与给定值之差是否为0
D:使用卡方统计量进行检验
答案: 【
8、多选题:
对于参数方法的独立样本检验,需要假设()
选项:
A:两总体独立
B:两总体均服从正态分布
C:两总体方差相等
D:样本随机抽取
答案: 【】
9、多选题:
对于均值比较的配对样本检验,需要假设()
选项:
A:两总体均服从正态分布
B:样本随机抽取
C:两总体独立
D:两总体均值之差均服从正态分布
答案: 【】
10、单选题:
在均值过程操作中,在“自变量列表”栏应选择()
选项:
A:时间变量
B:连续数值变量
C:分类变量
D:字符变量
答案: 【
第七章 单元测试
1、单选题:
方差分析的主要目的是判断()
选项:
A:分类自变量对因变量有无显著影响
B:各个样本数据之间是否有显著性差异
C:各总体是否存在方差
D:分类因变量对自变量有无显著影响
答案: 【
2、多选题:
方差分析的基本假设是()
选项:
A:样本是随机抽取的
B:各个总体方差相同
C:各个样本是独立
D:各个总体服从正态分布
答案: 【】
3、单选题:
方差分析是检验()
选项:
A:多个样本均值是否相等
B:多个样本方差是否相等
C:多个总体方差是否相等
D:多个总体均值是否相等
答案: 【
4、单选题:
单因素方差分析只涉及()
选项:
A:一个数值型因变量
B:一个数值型自变量
C:一个分类因变量
D:一个分类自变量
答案:
5、单选题:
多因素方差分析有()
选项:
A:多个分类因变量
B:多个分类自变量
C:多个数值型因变量
D:多个数值型自变量
答案: 【
6、单选题:
方差分析中,用于检测的F统计量是()
选项:
A:组间均方/总均方
B:组间平方和/组内平方和
C:组间均方/组内均方
D:组间平方和/总平方和
答案
7、单选题:
方差分析如果拒绝原假设,则意味着()
选项:
A:各个样本均值相同
B:各个总体均值相同
C:各个样本均值不同
D:各个总体均值不同
答案: 【
8、单选题:
方差分析中如果Levene检验拒绝原假设,则意味着()
选项:
A:各个总体方差相同
B:各个总体方差不同
C:各个样本方差不同
D:各个样本方差相同
答案: 【
9、多选题:
在多因素方差分析结果中,以下关系正确的是()
选项:
A:校正模型平方和等于各个自变量平方和加上交互项平方和。
B:总计平方和等于校正模型平方和加上截距平方和。
C:校正的总计平方和等于校正模型平方和加上误差平方和。
D:误差平方和等于校正模型平方和加上截距平方和。
答案: 【】
10、多选题:
以下结果判断正确的是()
选项:
A:如果校正模型的F检验显著,则该方差分析模型不成立。
B:如果某自变量的F检验显著,则该变量对因变量影响显著。
C:如果交互效应的F检验显著,则交互效应对因变量影响显著。
D:如果截距的F检验显著,则截距对因变量影响显著。
答案: 【】
第八章 单元测试
1、单选题:
对于非参数检验方法叙述正确的是()
选项:
A:不能做分布拟合检验
B:对总体的分布不作假设或仅作非常一般性假设
C:需估计总体参数
D:总体服从正态分布
答案: 【】
2、多选题:
能检验总体是否服从正态分布的菜单是()
选项:
A:【分析】→【非参数检验】→【旧对话框】→【1-样本K-S】
B:【分析】→【非参数检验】→【旧对话框】→【二项式】
C:【分析】→【非参数检验】→【旧对话框】→【游程】
D:【分析】→【非参数检验】→【旧对话框】→【卡方】
答案: 【】
3、单选题:
假定有一个容量为10的样本,对于它的每一个观察值,按一定的标准去分为两种符号,例如根据它是大于还是小于样本中位数(或均值)而给定某种符号,如大于记作A,小于记作B,如果我们把这些符号按抽样时被抽出的先后顺序排列,出现如下情况:ABAABAABBB,请问这组样本序列的游程数是()个。
选项:
A:3
B:5
C:4
D:6
答案: 【】
4、多选题:
“1-样本K-S”菜单提供了哪些检验分布()
选项:
A:泊松分布
B:指数分布
C:正态分布
D:均匀分布
答案: 【】
5、多选题:
二项式检验中,对于非二分值数据的检验,下列叙述正确的是()
选项:
A:组1是“<=割点”比例
B:检验比例是组2的比例
C:组2是“>割点”比例
D:检验比例是组1的比例
答案: 【】
6、多选题:
游程检验可以用于()
选项:
A:两总体均值相等性检验
B:两总体同分布检验
C:样本随机性检验
D:两总体方差齐性检验
答案: 【】
7、单选题:
为研究某种减肥茶减肥效果是否显著,数据分布未知,可以采用()分析方法。
选项:
A:2个独立样本
B:2个相关样本
C:K个相关样本
D:K个独立样本
答案:
8、单选题:
某村村民对四个村主任候选人(ABCD)的赞同与否进行调查,检验四个候选人在村民眼中有没有区别。可以采用()分析方法。
选项:
A:2个独立样本
B:K个独立样本
C:2个相关样本
D:K个相关样本
答案: 【
9、单选题:
有甲乙两种安眠药,独立观察20个病人,10人服甲药、10人服乙药,比较他们服药后延长的睡眠时间有无显著性差异?可以采用()分析方法。
选项:
A:2个相关样本
B:2个独立样本
C:K个相关样本
D:K个独立样本
答案: 【】
10、单选题:
10在一项健康试验中,利用三种生活方式在一个月时间内,记录了肥胖病人每日的减重量,检验三种生活方式对于减肥的效果是否有显著差异?可以采用()分析方法。
选项:
A:K个相关样本
B:K个独立样本
C:2个相关样本
D:2个独立样本
答案: 【
第九章 单元测试
1、多选题:
如果模型存在异方差性,仍然使用最小二乘法估计模型参数,则()
选项:
A:回归参数t检验失效
B:OLSE不再具有最小方差性
C:最小二乘估计量(OLSE)仍然具有线性无偏性
D:可采用加权最小二乘法消除异方差
答案: 【】
2、单选题:
使用时间序列数据建立回归模型,最有可能存在的问题是()。
选项:
A:自相关性
B:多重共线性
C:异方差性
D:非正态性
答案: 【】
3、多选题:
变量之间的依存关系,依据其紧密程度可分为()。
选项:
A:函数关系
B:直线关系
C:曲线关系
D:相关关系
答案: 【】
4、多选题:
对回归模型的检验,应包括()。
选项:
A:统计显著性检验
B:实际意义检验
C:拟合优度检验
D:计量意义检验
答案: 【】
5、单选题:
D-W检验,即杜宾-瓦尔森检验,用于检验时间序列回归模型的误差项中的一阶序列相关的统计量。如果DW值越接近于2,则()
选项:
A:表明存在着正的自相关
B:表明无自相关
C:无法表明任何意义
D:表明存在着负的自相关
答案: 【
6、单选题:
简单散点图是表示()变量间的统计关系的散点图。
选项:
A:多对
B:一对
C:两对
D:三对
答案: 【】
7、单选题:
在总体回归直线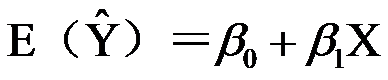 中,
中,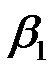 表示( )。
表示( )。
选项:
A:当Y增加一个单位时.X平均增加个单位
B:当X增加一个单位时.Y平均增加个单位
C:当X增加一个单位时.Y增加个单位
D:当Y增加一个单位时.X增加个单位
答案: 【
8、多选题:
下列()属于相关关系。
选项:
A:家庭收入和支出的关系
B:价格与销售额的关系(销量确定)
C:子女身高和父母身高的关系
D:圆面积和圆半径的关系
答案: 【】
9、多选题:
回归分析的主要内容有()
选项:
A:对回归模型进行评价与诊断
B:对因变量进行估计或预测
C:确定自变量和因变量
D:得到因变量与自变量之间的数学表达式
答案: 【】
10、多选题:
严重的不完全多重共线性会导致如下的严重问题()
选项:
A:重要的解释变量通不过t检验
B:估计量对样本非常敏感
C:估计量的方差和标准误差会增大
D:某个(或某些)系数的符号与常识(或实际意义)不相符
答案: 【
第十章 单元测试
1、多选题:
时间序列的构成要素()
选项:
A:长期趋势
B:不规则变动
C:循环变动
D:季节变动
答案: 【】
2、单选题:
有一组某企业5年各季度的销售数据,首先需要用到的数据预处理菜单是()
选项:
A:【数据】→【定义日期】
B:【转换】→【创建时间序列】
C:【数据】→【加权个案】
D:【转换】→【计算变量】
答案: 【
3、多选题:
关于移动平均说法正确的是()
选项:
A:可以消除不规则变动
B:可以消除循环变动
C:可以消除长期趋势
D:可以消除季节变动
答案: 【】
4、多选题:
关于移动平均项数,说法正确的是()
选项:
A:移动平均项数越大可能被剔除时间序列的其他影响因素
B:移动平均项数越大预测越精确
C:移动平均项数越大对不规则变动的去除越彻底
D:移动平均项数越大所得到的移动平均列也越光滑
答案: 【】
5、单选题:
用指数平滑法得到的t+1期的预测值等于()
选项:
A:t期的实际观察值与第t期指数平滑值的加权平均值
B:t期的实际观察值与第t+1期实际观察值的加权平均值
C:t+1期的实际观察值与第t期指数平滑值的加权平均值
D:t期的实际观察值与第t-1期指数平滑值的加权平均值
答案: 【
6、单选题:
对数据进行移动平均需要用到的菜单()
选项:
A:【转换】→【计算变量】
B:【分析】→【预测】→【创建模型】
C:【转换】→【创建时间序列】
D:【数据】→【加权个案】
答案: 【】
7、单选题:
对数据进行指数平滑分析需要用到的菜单()
选项:
A:【转换】→【创建时间序列】
B:【转换】→【计算变量】
C:【分析】→【预测】→【创建模型】
D:【数据】→【加权个案】
答案: 【
8、单选题:
可直接运用【分析】→【回归】菜单进行分析的时间序列数据是()
选项:
A:含有所有因素的长期趋势数据
B:含循环变动、不规则变动的长期趋势数据
C:含季节波动、不规则变动的长期趋势数据
D:含不规则变动的长期趋势数据
答案: 【】
9、单选题:
季节变动分析必须首先要做的一步操作是()
选项:
A:【转换】→【计算变量】
B:【数据】→【加权个案】
C:【转换】→【创建时间序列】
D:【数据】→【定义日期】
答案: 【】
10、多选题:
关于“季节性因素”即季节指数,说法正确的是()
选项:
A:季节指数大于1,说明该期为“旺季”,反之则为“淡季”。
B:原序列数值与移动平均数列数值的比率。
C:对含有季节波动的数据进行预测时,应先从原序列中用季节指数剔除季节波动后,再进行长期趋势的预测,即为最终预测结果。
D:刻画了现象在一个年度内各季(月)的变化特征。
答案: 【】


请先 !