第一章 单元测试
1、单选题:
以下选项不能展现数据集中趋势的是( )。
选项:
A:变异系数
B:众数
C:平均数
D:上四分位数
答案: 【变异系数】
2、单选题:
请计算数列“1、5、3、8、4、7、2、1”的中位数( )。
选项:
A:2
B:3
C:3.5
D:4
答案: 【3.5】
3、单选题:
某厂商希望了解区域内消费者对饮料品牌的需求数据,其最希望得到的是以下的哪种数据类型( )。
选项:
A:中位数
B:众数
C:四分位数
D:均值
答案: 【众数】
4、单选题:
如果一组变量值中有一项为0,则不能计算( )。
选项:
A:调和平均数
B:众数
C:中位数
D:算术平均数
答案: 【调和平均数】
5、单选题:
一组数据呈微偏分布,且知其均值为510,中位数为516,则可推算众数为( )
选项:
A:512
B:528
C:513
D:526
答案: 【528】
6、单选题:
下列哪项不是统计表的必要的构成元素( )
选项:
A:表头
B:表注
C:纵栏
D:横行
答案: 【表注】
7、单选题:
考察某个变量随时间的变化情况时,我们常规会作( )
选项:
A:散点图
B:直方图
C:箱线图
D:折线图
答案: 【折线图】
8、多选题:
下述能展现数据离散趋势的有( )
选项:
A:标准差
B:变异系数
C:极差
D:众数
E:四分位距
答案: 【标准差;
变异系数;
极差;
四分位距】
9、多选题:
下述哪种统计图通常能展现两个变量之间的关系( )
选项:
A:饼图
B:折线图
C:箱线图
D:散点图
E:条形图
答案: 【折线图;
散点图;
条形图】
10、判断题:
极差是最简单的变异指标,不易受极端值影响。( )
选项:
A:对
B:错
答案: 【错】
11、判断题:
R里用rbind合并两个数据框时,要求两个数据框行数相同。( )
选项:
A:错
B:对
答案: 【错】
第二章 单元测试
1、单选题:
( )表示由解释变量所解释的部分,表示x对y的线性影响。
选项:
A:总离差平方和
B:回归平方和
C:残差平方和
D:剩余平方和
答案: 【回归平方和】
2、单选题:
用一组有40个观测值的样本估计模型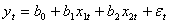 后,在0.05的显著性水平上对
后,在0.05的显著性水平上对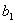 的显著性作t检验,则显著地不等于零的条件是其统计量t大于等于( )。
的显著性作t检验,则显著地不等于零的条件是其统计量t大于等于( )。
选项:
A: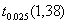
B: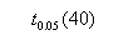
C: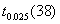
D: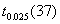
答案: 【
】
3、单选题:
判定系数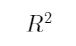 指的是( )
指的是( )
选项:
A:回归平方和占残差平方和的比重
B:残差平方和占总离差平方和的比重
C:回归平方和占总离差平方和的比重
D:总离差平方和占回归平方和的比重
答案: 【回归平方和占总离差平方和的比重】
4、单选题:
在回归分析中,用来检验模型拟合优度的统计量是( )。
选项:
A:判定系数
B:t统计量
C:F统计量
D:三个都是
答案: 【判定系数】
5、单选题:
在模型 的回归结果分析中,有F=263489.23,对应的p值为0.0000,这表明( )。
的回归结果分析中,有F=263489.23,对应的p值为0.0000,这表明( )。
选项:
A:
解释变量 、
、
对被解释变量
 的影响均不显著
的影响均不显著
B:
解释变量 对被解释变量
对被解释变量 的影响是显著的
的影响是显著的
C:
解释变量
、

对被解释变量

的联合影响是显著的
D:
解释变量
对被解释变量
 的影响是显著的
的影响是显著的
答案: 【
解释变量、
对被解释变量
的联合影响是显著的
】
6、多选题:
判定系数
与调整后的判定系数
 之间的关系描述不正确的有( )。
之间的关系描述不正确的有( )。
选项:
A:
模型中包含的解释变量的个数越多
,与
 相差越大
相差越大
B:

与

均非负
C:

可能大于

D:
判断多元线性回归模型拟合优度时,使用
答案: 【
模型中包含的解释变量的个数越多,与
相差越大
;
与
均非负
;
可能大于
】
7、多选题:
若模型
满足古典假定,则下列各式成立的有( )。
选项:
A:

B:

C:

D:

答案: 【
;
;
】
8、多选题:
关于多重判定系数
的公式正确的有( )。
选项:
A:

B:

C:

D:

答案: 【
;
;
】
9、判断题:
使用普通最小二乘法估计模型时,所选择的回归模型使得所有观测值的残差和达到最小。( )
选项:
A:对
B:错
答案: 【错】
10、判断题:
调整后的判定系数是关于解释变量个数的单调递增函数。( )
选项:
A:对
B:错
答案: 【错】
第三章 单元测试
1、单选题:
(1)为从社会最终产品出制定国民经济计划,提供了一种科学方法(2)能够成为加强国民经济综合平衡的重要工具以上属于投入产出模型在制定国民经济计划中的作用为:( )
选项:
A:(2)
B:(1)
C:(1)(2)
D:一个都不是
答案: 【】
2、单选题:
∑(vj+mj)/∑∑Xij 是分析 :( ), i=1, j=1。
选项:
A:国民收入与物资消耗的比例
B:消费数量与社会总成本的比例
C:消费数量与劳动报酬的比例
D:社会总产品与社会化成本的比例
答案: 【】
3、单选题:
直接消耗系数最为主要的影响因素是( )的变化
选项:
A:人员流动
B:生产技术
C:设备折旧
D:时间
答案: 【】
4、多选题:
产品投入产出模型在加强国民经济综合平衡方面表现在( )
选项:
A:检验社会生产与社会需要之间的平衡关系
B:进行某些国民经济大型项目建设与整个国民经济发展之间的平衡分析
C:可以检验国民经济计划中各部门之间的协调情况
D:利用数据,可以更好地分析各部门之间的比例关系
答案: 【】
5、多选题:
一般来说,在设计投入产出表的部门分类的大小时,主要考虑下面的元素:( )
选项:
A:目前实际中宏观管理和统计指标划分的粗细程度;
B:目前国家宏观经济管理的实际水平;
C:编制投入产出表工作量的大小。
D:目前实际中经济管理和统计人员的业务水平和能力;
答案: 【】
6、多选题:
投入产出表所要求的部门分类原则为( )
选项:
A:经济用途相同
B:工艺技术相同
C:上面答案全部错误
D:产品的中间投入结构相同
答案: 【】
7、多选题:
投入产出分析的基本假定有( )
选项:
A:消耗系数相对稳定性假定
B:静态性假定
C:相加性假定
D:同质性假定
答案: 【
8、多选题:
列昂惕夫创立的投入产出分析方法有( )
选项:
A:在投入产出表的基础上,建立数学模型,用逆矩阵求解
B:计算各种投入产出系数
C:编制投入产出表
D:投入产出调查
答案: 【】
9、判断题:
投入产出表的行反映各部门产品的实物运动过程,而列则反映各部门产品的价值形成过程。( )
选项:
A:错
B:对
答案: 【】
10、判断题:
在实物投入产出表中,是以产品来进行分类的,其计量单位则是以实物单位来计量的。( )
选项:
A:对
B:错
答案: 【】
第四章 单元测试
1、单选题:
下列选项中是标准概率矩阵的是( )
选项:
A: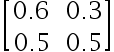
B: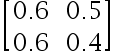
C: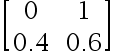
D: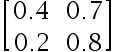
答案: 【
】
2、单选题:
A、B、C三个产品的客户流量的一步转移概率矩阵为  ,则系统经历1个单位时间后原来C产品顾客仍购买此产品的概率为( )
,则系统经历1个单位时间后原来C产品顾客仍购买此产品的概率为( )
选项:
A:0.4
B:0.34
C:0.6
D:0.3
答案: 【】
3、单选题:
马氏链的一步转移概率矩阵为标准概率矩阵是马氏链必有稳定状态的( )
选项:
A:充分非必要条件
B:充分必要条件
C:充分条件
D:必要条件
答案: 【】
4、单选题:
随机过程的状态和状态转移的统计特性可用状态转移的( )描述。
选项:
A:累计频数
B:累计频率
C:频数
D:概率
答案: 【】
5、多选题:
下列选项中是标准概率矩阵的是( )
选项:
A: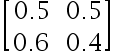
B: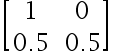
C: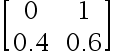
D: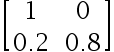
答案: 【
】
6、多选题:
下列选项中不是标准概率矩阵的是( )
选项:
A: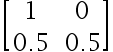
B: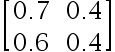
C: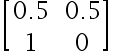
D: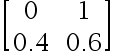
答案: 【
】
7、判断题:
A、B、C三个产品的客户流量的一步转移概率矩阵为  ,则系统经历1个单位时间后原来C产品顾客仍购买此产品的概率为0.7。( )
,则系统经历1个单位时间后原来C产品顾客仍购买此产品的概率为0.7。( )
选项:
A:错
B:对
答案: 【】
8、判断题:
矩阵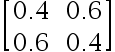 是标准概率矩阵。( )
是标准概率矩阵。( )
选项:
A:对
B:错
答案: 【
9、判断题:
矩阵 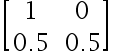 不是标准概率矩阵。( )
不是标准概率矩阵。( )
选项:
A:错
B:对
答案: 【】
10、判断题:
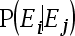 表示由状态
表示由状态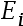 经过一步转移到状态
经过一步转移到状态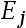 的一步转移概率。( )
的一步转移概率。( )
选项:
A:对
B:错
答案: 【】
第五章 单元测试
1、单选题:
学习DEA,以下哪个选项不是必要的前期知识储备( )。
选项:
A:厂商理论
B:运筹学
C:统计学
D:均衡理论
答案: 【】
2、单选题:
CCR模型中,决策单元A的效率为0.65,决策单元A的效率为0.6,则( )。
选项:
A:B比A效率高
B:A和B效率一样
C:无法判断
D:A比B效率高
答案: 【】
3、单选题:
在CCR模型下,某决策单元效率为1,则该决策单元( )。
选项:
A:规模有效
B:纯技术有效
C:技术无效
D:技术有效
答案: 【
4、单选题:
如果决策单元技术效率计算为1,纯技术效率计算为0.2,则规模效率是( )。
选项:
A:0.8
B:无法得出
C:5
D:0.2
答案: 【】
5、单选题:
若某决策单元在生产前沿面上,则其( )
选项:
A:技术无效
B:技术有效
C:规模有效
D:无法判断
答案: 【
6、单选题:
下列哪个模型是Banker等学者提出的( )
选项:
A:SBM
B:CCR
C:BCC
D:Super-SBM
答案: 【
7、单选题:
下列说法正确的是( )
选项:
A:BBC模型是径向模型
B:上面三个模型都是非径向模型
C:CCR模型是非径向模型
D:SBM模型是径向模型
答案: 【】
8、多选题:
下列说法正确的是( )
选项:
A:技术效率不小于规模效率
B:技术效率大于纯技术效率
C:规模效率不可能小于纯技术效率
D:技术效率大于规模效率
E:技术效率不小于纯技术效率
答案: 【】
9、判断题:
数据包络分析方法是当前唯一测度效率的方法。( )
选项:
A:对
B:错
答案: 【】
10、判断题:
DEA的学习需要我们深刻掌握高等代数的相关内容和方法。( )
选项:
A:对
B:错
答案: 【】
第六章 单元测试
1、单选题:
对于一阶滑动平均模型MA(1): 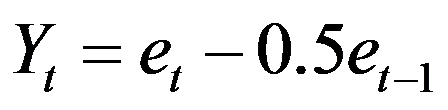 ,则其一阶自相关系数为( )。
,则其一阶自相关系数为( )。
选项:
A: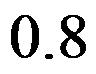
B: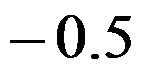
C: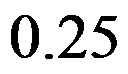
D: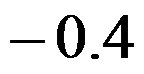
答案:
】
2、单选题:
MA(q)模型序列的预测方差为下列哪项( )
选项:
A: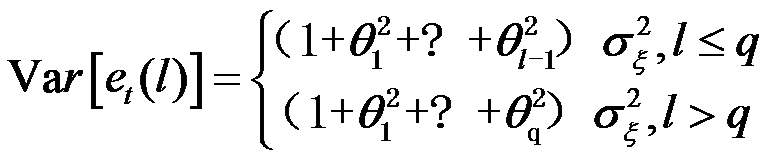
B: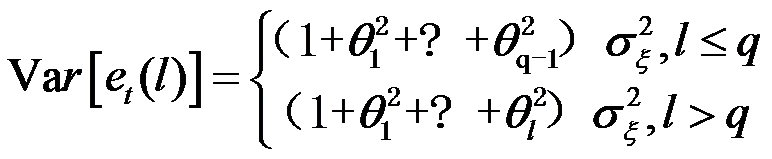
C: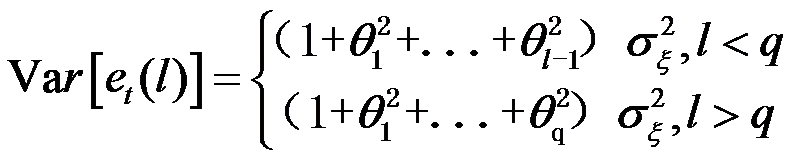
D: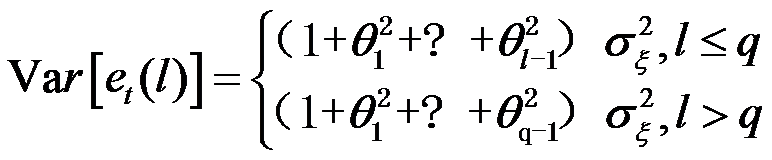
答案: 【
】
3、单选题:
ARMA(p,q)模型的平稳条件是( )
选项:
A: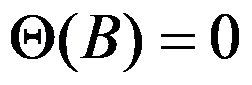 的根都在单位圆内;
的根都在单位圆内;
B: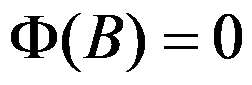 的根都在单位圆外;
的根都在单位圆外;
C: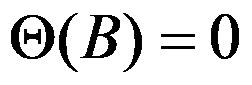 的根都在单位圆外;
的根都在单位圆外;
D: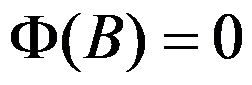 的根都在单位圆内。
的根都在单位圆内。
答案: 【
】
4、单选题:
利用自相关图判断一个时间序列的平稳,下列说法正确的是( )
选项:
A:自相关系数一直为正。
B:在相关图上,呈现明显的三角对称性。
C:自相关系数很快衰减为零。
D:自相关系数衰减为零的速度缓慢。
答案: 【】
5、单选题:
利用时序图对时间序列的平稳性进行检验,下列说法正确的是( )
选项:
A:如果时序图呈现明显的递增态势,那么这个时间序列就是平稳序列。
B:如果时序图呈现明显的周期态势,那么这个时间序列就是平稳序列。
C:如果时序图总是围绕一个常数波动,而且其波动范围有限,那么这个时间序列是平稳序列。
D:通过时序图不能够精确判断一个序列的平稳与否。
答案: 【】
6、多选题:
有关DF检验的说法正确的是( )。
选项:
A:DF检验的零假设是“被检验时间序列平稳”
B:DF检验的零假设是“被检验时间序列非平稳”
C:DF检验是单侧检验
D:DF检验是双侧检验
答案: 【】
7、判断题:
ARMA(p,q)模型的自相关函数和偏自相关函数均表现为拖尾( )
选项:
A:错
B:对
答案: 【】
8、判断题:
经过D阶差分后变成平稳的ARMA(p,q)过程时,原过程称为ARIMA(p,d,q)。( )
选项:
A:对
B:错
答案: 【】
9、判断题:
同一个序列可以构造两个不同的ARMA模型,两个模型都显著有效,那么到底该选择哪个模型用于统计推断,所用的选择准则主要有AIC准则和SC准则。利用这两个准则进行选择时,选择取值最大的即可。( )
选项:
A:错
B:对
答案: 【】
10、判断题:
单位根检验的方法只有DF检验和ADF检验方法。( )
选项:
A:对
B:错
答案: 】
第七章 单元测试
1、单选题:
下列说法正确的是( )。
选项:
A:类平均法比重心法使空间浓缩
B:最短距离法比最长距离法使空间扩张
C:离差平方和法比类平均法使空间扩张
D:离差平方和法比重心法使空间浓缩
答案: 【】
2、单选题:
关于主成分,下列说法正确的是( )。
选项:
A:各主成分之间互不相关
B:主成分的方差都为1
C:主成分是原始变量的组合
D:主成分的总方差大于原始变量的总方差
答案: 【】
3、单选题:
主成分的协方差阵为( )
选项:
A:对角阵
B:单位阵
C:对称阵
D:非正定矩阵
答案: 【】
4、多选题:
根据聚类原理,聚类分析分为( )
选项:
A:样品聚类
B:逐步聚类
C:系统聚类
D:快速聚类
E:变量聚类
答案: 【】
5、多选题:
因子分析分为( )两类
选项:
A:Q型因子分析
B:对因子载荷系数矩阵做因子分析
C:R型因子分析
D:对协方差矩阵作因子分析
E:对相关系数矩阵作因子分析
答案: 【】
6、多选题:
方差贡献率越大说明这个主成分( )
选项:
A:综合原始变量信息的能力越弱
B:地位越重要
C:对某个原始变量的信息提取程度越高
D:地位越不重要
E:综合原始变量信息的能力越强
答案: 【】
7、判断题:
兰氏距离不仅克服了明氏距离与各指标的量纲有关的缺点,而且也考虑了变量间的相关性。 ( )
选项:
A:对
B:错
答案: 【】
8、判断题:
主成分y的协差阵为对角矩阵。( )
选项:
A:对
B:错
答案: 【】
9、判断题:
因子载荷阵经过正交旋转后,各变量的共性方差和各个因子的方差贡献都发生了变化。( )
选项:
A:对
B:错
答案: 【】
10、判断题:
因子载荷阵是唯一的。( )
选项:
A:对
B:错
答案: 【】
第八章 单元测试
1、单选题:
决策树学习算法主要包括①决策树的生成、②决策树的剪枝、③特征选择等3个部分,3个部分顺序正确的是( )
选项:
A:②①③
B:③②①
C:①②③
D:③①②
答案: 【】
2、单选题:
可以将所有含缺失值NA的观测都删去的函数是( )
选项:
A:na.pass
B:na.contiguous
C:na.omit
D:na.fail
答案: 【】
3、单选题:
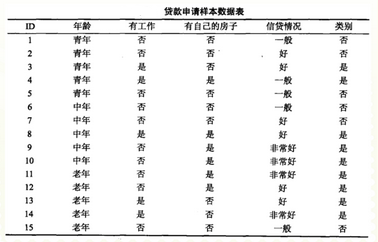 如图数据,研究是否批准贷款申请(“类别”变量)。经计算年龄、有工作、有自己的房子、信贷情况4个特征的信息增益依次为0.083、0.324、0.420和0.363,根据ID3决策树学习算法应该选择( )为划分标志。
如图数据,研究是否批准贷款申请(“类别”变量)。经计算年龄、有工作、有自己的房子、信贷情况4个特征的信息增益依次为0.083、0.324、0.420和0.363,根据ID3决策树学习算法应该选择( )为划分标志。
选项:
A:年龄
B:有自己的房子
C:信贷情况
D:有工作
答案: 【】
4、单选题:
如果一个 SVM 模型出现欠拟合,那么下列哪种方法能解决这一问题?( )
选项:
A:同时减少惩罚参数 C的值和核系数(gamma参数)
B:减小核系数(gamma参数)
C:减小惩罚参数 C 的值
D:增大惩罚参数 C 的值
答案: 【
5、单选题:
评估完模型之后,发现随机森林模型存在高偏差(high bias),应该如何解决?( )
选项:
A:上面说法都正确
B:增加模型的特征数量
C:减少模型的特征数量
D:增加样本数量
答案: 【
6、单选题:
假设我们使用原始的非线性可分的 Soft-SVM 优化目标函数。我们需要做什么来保证得到的模型是线性可分离的?( )
选项:
A:C 正无穷大
B:C = 0
C:C = 1
D:C 负无穷大
答案: 【】
7、多选题:
下列哪些R包可以进行决策树分析( )
选项:
A:party
B:dplyr
C:rpart
D:Rmisc
E:tree
答案: 【】
8、判断题:
CART决策树算法以信息增益率准则来选择划分属性。( )
选项:
A:对
B:错
答案: 【】
9、判断题:
在训练完 SVM 之后,我们可以只保留支持向量,而舍去所有非支持向量。仍然不会影响模型分类能力。这句话是否正确?( )
选项:
A:对
B:错
答案: 【】
10、判断题:
随机森林模型是使用随机特征子集来创建中间树的( )
选项:
A:错
B:对
答案: 【】
11、判断题:
随机森林模型的中间树不是相互独立的( )
选项:
A:错
B:对
答案: 【】
第九章 单元测试
1、单选题:
资金流量核算是以 ( )进行分类核算的。
选项:
A:机构部门
B:产品部门
C:常住单位
D:产业部门
答案: 【
2、单选题:
在资金流量核算核算表中,每个机构部门列的“使用”记录的是 ( )
选项:
A:支出,资金流入
B:收入,资金流出
C:收入,资金流入
D:支出,资金流出
答案: 【】
3、单选题:
下面属于收入分配经济行为的是( )
选项:
A:购买消费品
B:单位为员工缴纳社会保障缴款
C:购买固定资产
D:出售价格上涨的股票
答案: 【】
4、单选题:
我国资金流量核算起点是( )
选项:
A:总储蓄
B:净金融投资
C:总产出
D:增加值
答案: 【
5、多选题:
下列属于收入分配和使用核算范围的有( )
选项:
A:股票交易中所获取的价差
B:野生动植物的生长变化
C:企业向学校捐款
D:自给性的家务劳动
E:农民自产自用的粮食
答案: 【】
6、多选题:
我国资金流量核算的对象包括( )
选项:
A:金融交易
B:收入使用交易
C:货物和服务交易
D:非金融投资
E:收入分配交易
答案: 【】
7、多选题:
目前资金流量核算的范围有以下类型( )
选项:
A:以增加值为起点,包括收入分配与使用、非金融投资及金融交易
B:上面说法均正确
C:以总产出为起点,包括货物和服务交易、投入产出、非金融投资和金融交易
D:就严格的金融交易编制资金流量表
E:以总储蓄为起点,包括资金筹集和金融交易
答案: 【
8、判断题:
贵重物品属于非金融投资的一部分,对持有者来说,因价格上升而使物品增值应计入本期非金融投资。( )
选项:
A:对
B:错
答案: 【】
9、判断题:
资金流量表是一个二维矩阵,可以从行向上分析部门内部的交易特征,也可以从列向上分析部门之间的结构关系。( )
选项:
A:错
B:对
答案: 【】
10、判断题:
某企业出租机器设备,由于机器设备是该企业的固定资产,因此其租金应记为财产收入。( )
选项:
A:错
B:对
答案: 【】


评论0