第一章 单元测试
1、判断题:
回归和分类都是有监督学习问题。( )
选项:
A:对
B:错
答案: 【对】
2、判断题:
输出变量为有限个离散变量的预测问题是回归问题;输出变量为连续变量的预测问题是分类问题。( )
选项:
A:错
B:对
答案: 【错】
3、单选题:
关于“回归(Regression)”和“相关(Correlation)”,下列说法正确的是?注意:x 是自变量,y 是因变量。( )
选项:
A:回归在 x 和 y 之间是非对称的,相关在 x 和 y 之间是互为对称的
B:回归在 x 和 y 之间是对称的,相关在 x 和 y 之间是非对称的
C:回归和相关在 x 和 y 之间都是互为对称的
D:回归和相关在 x 和 y 之间都是非对称的
答案: 【回归在 x 和 y 之间是非对称的,相关在 x 和 y 之间是互为对称的】
4、判断题:
如果一个经过训练的机器学习模型在测试集上达到 100% 的准确率,这就意味着该模型将在另外一个新的测试集上也能得到 100% 的准确率。( )
选项:
A:对
B:错
答案: 【错】
5、判断题:
机器学习学得的模型适用于新样本的能力,称为”泛化”能力,这是针对分类和回归等监督学习任务而言的,与聚类这样的无监督学习任务无关。( )
选项:
A:对
B:错
答案: 【错】
6、判断题:
机器学习时,我们通常假设样本空间中的全体样本都服从某个未知”分布”,并且我们获得的每个样本都是独立地从这个分布上采样获得的。( )
选项:
A:对
B:错
答案: 【对】
7、判断题:
从归纳偏好一般性原则的角度看,”奥卡姆剃刀” (Occam’s razor)准则与“大道至简”说的是相同的道理。( )
选项:
A:错
B:对
答案: 【对】
8、多选题:
以下方法或系统属于”符号主义” (symbolism)学习技术的是( )
选项:
A:”结构学习系统”
B:”概念学习系统”
C:”基于逻辑的归纳学习系统“
D:支持向量机
答案: 【”结构学习系统”;”概念学习系统”;”基于逻辑的归纳学习系统“】
9、多选题:
以下方法或技术属于统计学习范畴的是( )
选项:
A:支持向量机
B:核方法
C:Hopfield神经网络
D:感知机
答案: 【支持向量机;核方法】
10、判断题:
归纳学习相当于”从样例中学习”,即从训练样例中归纳出学习结果。( )
选项:
A:错
B:对
答案: 【对】
第二章 单元测试
1、判断题:
回归问题和分类问题都有可能发生过拟合。( )
选项:
A:对
B:错
答案: 【对】
2、多选题:
对于k折交叉验证, 以下对k的说法正确的是 ( )
选项:
A:选择更大的k, 就会有更小的bias (因为训练集更加接近总数据集)
B:k越大, 不一定越好, 选择大的k会加大评估时间
C:在选择k时, 要最小化数据集之间的方差
D:k越大越好
答案: 【选择更大的k, 就会有更小的bias (因为训练集更加接近总数据集);k越大, 不一定越好, 选择大的k会加大评估时间;在选择k时, 要最小化数据集之间的方差】
3、多选题:
小明参加Kaggle某项大数据竞赛,他的成绩在大赛排行榜上原本居于前20,后来他保持特征不变,对原来的模型做了1天的调参,将自己的模型在自己本地测试集上的准确率提升了3%,然后他信心满满地将新模型的预测结果更新到了大赛官网上,结果懊恼地发现自己的新模型在大赛官方的测试集上准确率反而下降了。对此,他的朋友们展开了讨论,下列说法正确的是( )
选项:
A:小明这个有可能是由于过拟合导致的
B:小明可以考虑一下,使用交叉验证来验证一下是否发生了过拟合
C:从机器学习理论的角度,这样的情况不应该发生,应该去找大赛组委会反应
D:小明应该乖乖使用默认的参数就行了,调参是不可能有收益的
答案: 【小明这个有可能是由于过拟合导致的;小明可以考虑一下,使用交叉验证来验证一下是否发生了过拟合】
4、多选题:
下列哪种方法可以用来减小过拟合?( )
选项:
A:减小模型的复杂度
B:更多的训练数据
C:L1 正则化
D:L2 正则化
答案: 【减小模型的复杂度;更多的训练数据;L1 正则化;L2 正则化】
5、单选题:
下列关于 bootstrap 说法正确的是?( )
选项:
A:从总的 N 个样本中,有放回地抽取 n 个样本(n < N)
B:从总的 M 个特征中,无放回地抽取 m 个特征(m < M)
C:从总的 N 个样本中,无放回地抽取 n 个样本(n < N)
D:从总的 M 个特征中,有放回地抽取 m 个特征(m < M)
答案: 【从总的 N 个样本中,有放回地抽取 n 个样本(n < N)】
6、单选题:
评估完模型之后,发现模型存在高偏差(high bias),应该如何解决?( )
选项:
A:减少模型的特征数量
B:增加样本数量
C:增加模型的特征数量
答案: 【增加模型的特征数量】
第三章 单元测试
1、单选题:
如果我们说“线性回归”模型完美地拟合了训练样本(训练样本误差为零),则下面哪个说法是正确的?( )
选项:
A:选项中的答案都不对
B:测试样本误差不可能为零
C:测试样本误差始终为零
答案: 【】
2、单选题:
下列关于线性回归分析中的残差(Residuals)说法正确的是?( )
选项:
A:残差均值总是大于零
B:残差均值总是小于零
C:选项中的说法都不对
D:残差均值总是为零
答案: 【】
3、多选题:
下列哪些假设是我们推导线性回归参数时遵循的?( )
选项:
A:X 与 Y 有线性关系(多项式关系)
B:误差一般服从 0 均值和固定标准差的正态分布
C:X 是非随机且测量没有误差的
D:模型误差在统计学上是独立的
答案: 【】
4、单选题:
一般来说,下列哪种方法常用来预测连续独立变量?( )
选项:
A:逻辑回归
B:线性回归和逻辑回归都行
C:线性回归
答案: 【】
5、单选题:
 上图中哪一种偏移,是我们在最小二乘直线拟合的情况下使用的?图中横坐标是输入 X,纵坐标是输出 Y。( )
上图中哪一种偏移,是我们在最小二乘直线拟合的情况下使用的?图中横坐标是输入 X,纵坐标是输出 Y。( )
选项:
A:垂向偏移(perpendicular offsets)
B:两种偏移都可以
C:垂直偏移(vertical offsets)
答案: 【】
6、单选题:
加入使用逻辑回归对样本进行分类,得到训练样本的准确率和测试样本的准确率。现在,在数据中增加一个新的特征,其它特征保持不变。然后重新训练测试。则下列说法正确的是?( )
选项:
A:测试样本准确率一定增加或保持不变
B:训练样本准确率一定增加或保持不变
C:训练样本准确率一定会降低
D:测试样本准确率一定会降低
答案: 【】
7、单选题:
点击率预测是一个正负样本不平衡问题(例如 99% 的没有点击,只有 1% 点击)。假如在这个非平衡的数据集上建立一个模型,得到训练样本的正确率是 99%,则下列说法正确的是?( )
选项:
A:无法对模型做出好坏评价
B:模型正确率很高,不需要优化模型了
C:模型正确率并不高,应该建立更好的模型
答案: 【】
第四章 单元测试
1、多选题:
在决策树分割结点的时候,下列关于信息增益说法正确的是( )
选项:
A:纯度高的结点需要更多的信息来描述它
B:信息增益可以用”1比特-熵”获得
C:如果选择一个属性具有许多特征值, 那么这个信息增益是有偏差的
答案: 【】
2、判断题:
如果自变量 X 和因变量 Y 之间存在高度的非线性和复杂关系,那么树模型很可能优于经典回归方法。( )
选项:
A:对
B:错
答案: 【】
3、判断题:
在决策树学习过程中,用属性α 对样本集D 进行划分所获得的”信息增益”越大,则意味着使用属性α 来进行划分所获得的”纯度提升”越大。( )
选项:
A:对
B:错
答案: 【】
4、多选题:
对于划分属性选择,以下说法正确的是( )
选项:
A:选项中说法都不对
B:C4.5算法并不是直接选择增益率最大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C:增益率准则对可取值数目较少的属性有所偏好
D:信息增益准则对可取值数目较多的属性有所偏好
答案: 【】
5、判断题:
数据集D 的纯度可用它的基尼值来度量,基尼值越小,则数据集D 的纯度越高。( )
选项:
A:错
B:对
答案: 【】
第五章 单元测试
1、单选题:
假定你在神经网络中的隐藏层中使用激活函数 X。在特定神经元给定任意输入,你会得到输出 -0.01。X 可能是以下哪一个激活函数? ( )
选项:
A:ReLU
B:Sigmoid
C:选项中都有可能
D:tanh
答案: 【】
2、单选题:
在回归模型中,下列哪一项在权衡欠拟合(under-fitting)和过拟合(over-fitting)中影响最大?( )
选项:
A:更新权重 w 时,使用的是矩阵求逆还是梯度下降
B:多项式阶数
C:使用常数项
答案: 【】
3、多选题:
深度神经网络中常用Relu函数作为激活函数,其好处是:( )
选项:
A:选项中没有正确答案
B:收敛快
C:具有稀疏特性
D:求梯度简单
答案: 【】
4、单选题:
梯度爆炸问题是指在训练深度神经网络的时候,梯度变得过大而损失函数变为无穷。在RNN中,下面哪种方法可以较好地处理梯度爆炸问题?( )
选项:
A:选项中的方法都不行
B:梯度裁剪
C:用改良的网络结构比如LSTM和GRUs
D:Dropout
答案: 【】
5、单选题:
Dropout技术在下列哪种神经层中将无法发挥显著优势?( )
选项:
A:卷积层
B:仿射层(全连接层)
C:RNN层
答案: 【
第六章 单元测试
1、单选题:
如果SVM模型欠拟合, 以下方法哪些可以改进模型( )
选项:
A:减小核函数的参数
B:减小惩罚参数C的值
C:增大惩罚参数C的值
答案: 【】
2、判断题:
在训练完 SVM 之后,我们可以只保留支持向量,而舍去所有非支持向量,仍然不会影响模型分类能力。( )
选项:
A:错
B:对
答案: 【】
3、多选题:
关于SVM与感知机,以下说法正确的是:( )
选项:
A:感知机只用于线性分类,SVM可用于线性和非线性分类
B:优化方法方面,感知机采用梯度下降法,而SVM采用不等式约束结合拉格朗日乘子
C:损失函数方面,感知机采用的是误分类,易造成过拟合,而SVM采用间隔最大化(合页损失函数),一定程度上可避免过拟合
D:都是用于分类的监督学习算法
答案: 【】
4、判断题:
支持向量机SVM是结构风险最小化模型,而逻辑回归LR是经验风险最小化模型。( )
选项:
A:错
B:对
答案: 【】
5、判断题:
逻辑回归LR是参数模型,支持向量机SVM是非参数模型。( )
选项:
A:错
B:对
答案: 【】
6、多选题:
关于SVM如何选用核函数,下列说法正确的是:( )
选项:
A:非线性核主要用于线性不可分以及特征数较少样本量一般的情况
B:高斯核和tanh核都属于非线性核,而且高斯核还可以把原始维度映射到无穷多维
C:选项中说法都不对
D:线性核主要用于线性可分以及样本数与特征数差不多的情况
答案: 【】
第七章 单元测试
1、多选题:
下列关于极大似然估计(Maximum Likelihood Estimate,MLE),说法正确的是( )
选项:
A:MLE 总是存在
B:如果 MLE 存在,那么它的解可能不是唯一的
C:如果 MLE 存在,那么它的解一定是唯一的
D:MLE 可能并不存在
答案: 【】
2、判断题:
朴素贝叶斯属于生成式模型,而SVM和决策树属于判别式模型。( )
选项:
A:错
B:对
答案: 【】
3、判断题:
朴素贝叶斯分类器有属性条件独立的假设前提。( )
选项:
A:错
B:对
答案: 【】
4、多选题:
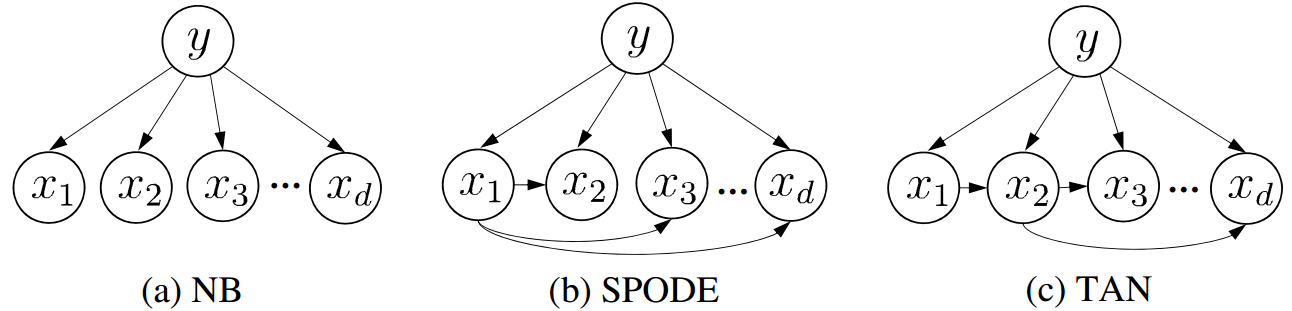
上面三个贝叶斯模型中,属性之间存在依赖关系的是:( )
选项:
A:(c)
B:都不存在
C:(a)
D:(b)
答案: 【】
5、多选题:
关于贝叶斯网络,以下说法正确的是:( )
选项:
A:贝叶斯网络是无向有环图模型
B:贝叶斯网络是有向无环图模型
C:贝叶斯网络是一种概率图模型
D:贝叶斯网络又称信念网络
答案: 【】
第八章 单元测试
1、单选题:
下面关于 Random Forest 和 Gradient Boosting Trees 说法正确的是?( )
选项:
A:无论任何数据,Gradient Boosting Trees 总是优于 Random Forest
B:Random Forest 的中间树不是相互独立的,而 Gradient Boosting Trees 的中间树是相互独立的
C:两者都使用随机特征子集来创建中间树
D:在 Gradient Boosting Trees 中可以生成并行树,因为它们是相互独立的
答案: 【】
2、单选题:
数据科学家经常使用多个算法进行预测,并将多个机器学习算法的输出(称为“集成学习”)结合起来,以获得比所有个体模型都更好的更健壮的输出。则下列说法正确的是?( )
选项:
A:基本模型都来自于同一算法
B:基本模型之间相关性高
C:集成方法中,使用加权平均代替投票方法
D:基本模型之间相关性低
答案: 【】
3、多选题:
以下方法属于集成学习方法的是( )
选项:
A:boosting
B:bootstrapping
C:stacking
D:bagging
答案: 【】
4、多选题:
如果用“三个臭皮匠顶个诸葛亮”来比喻集成学习的话,那么对三个臭皮匠的要求可能是:( )
选项:
A:选项中说法都不对
B:三个臭皮匠的优点各不相同
C:三个臭皮匠不能太差,每个人考试都能及格
D:三个臭皮匠的缺点各不相同
答案: 【】
5、判断题:
集成学习中个体学习器的多样性不宜高,否则容易顾此失彼,降低系统的总体性能。( )
选项:
A:对
B:错
答案: 【】
第九章 单元测试
1、单选题:
向量x=[1,2,3,4,-9,0]的L1范数是 ( )
选项:
A:20
B:19
C:4
D:5
答案: 【】
2、多选题:
如何在监督式学习中使用聚类算法?( )
选项:
A:在应用监督式学习算法之前,可以将其类别 ID 作为特征空间中的一个额外的特征
B:在应用监督式学习算法之前,不能将其类别 ID 作为特征空间中的一个额外的特征
C:首先,可以创建聚类,然后分别在不同的集群上应用监督式学习算法
D:在应用监督式学习之前,不能创建聚类
答案: 【】
3、多选题:
下列聚类方法属于原型聚类的是 ( )
选项:
A:DBSCAN
B:高斯混合聚类
C:学习向量量化LVQ
D:K-Means 算法
答案: 【】
4、多选题:
K-Means聚类的主要缺点有:( )
选项:
A:对于非凸数据集或类别规模差异太大的数据效果不好
B:K值很难确定
C:聚类效果依赖于聚类中心的初始化
D:原理复杂,不容易实现
E:对噪音和异常点敏感
答案: 【】
5、判断题:
k均值算法和”学习向量量化”都是原型聚类方法,也都属于无监督学习方法。( )
选项:
A:对
B:错
答案: 【】
第十章 单元测试
1、单选题:
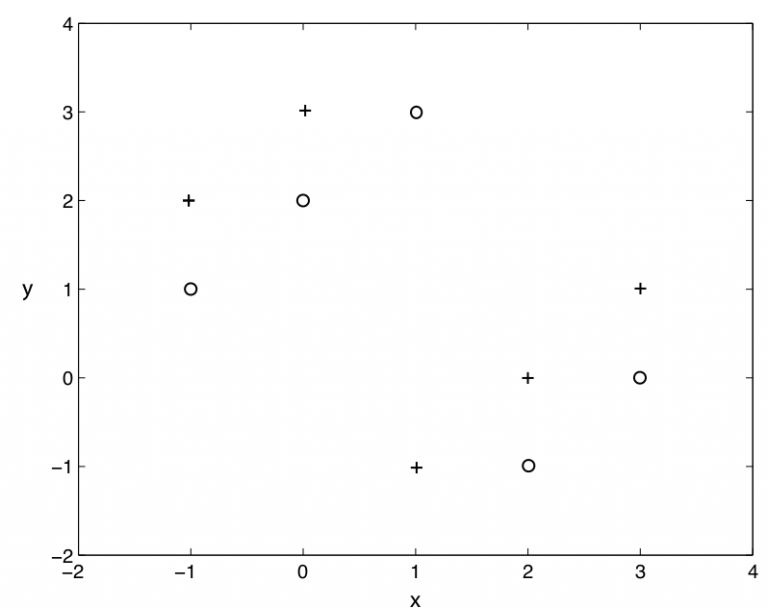
使用k=1的kNN算法, 下图二分类问题, “+” 和 “o” 分别代表两个类, 那么, 用仅拿出一个测试样本的交叉验证方法, 交叉验证的错误率是( )
选项:
A:0% 到 100%
B:0%
C:100%
答案: 【】
2、单选题:
下列说法错误的是?( )
选项:
A:利用拉格朗日函数能解带约束的优化问题
B:沿负梯度的方向一定是最优的方向
C:当目标函数是凸函数时,梯度下降算法的解一般就是全局最优解
D:进行 PCA 降维时,需要计算协方差矩阵
答案: 【】
3、单选题:
以下哪些方法不可以直接来对文本分类?( )
选项:
A:决策树
B:支持向量机
C:kNN
D:K-Means
答案: 【
4、多选题:
下列哪些算法可以用来够造神经网络?( )
选项:
A:线性回归
B:kNN
C:逻辑回归
D:选项中都不行
答案: 【
5、多选题:
我们想要训练一个 ML 模型,样本数量有 100 万个,特征维度是 5000,面对如此大数据,如何有效地训练模型?( )
选项:
A:使用 PCA 算法减少特征维度
B:选项中都不对
C:尝试使用在线机器学习算法
D:对训练集随机采样,在随机采样的数据上建立模型
答案: 【】
6、单选题:
 上图中,主成分的最佳数目是多少?( )
上图中,主成分的最佳数目是多少?( )
选项:
A:10
B:无法确定
C:20
D:30
答案: 【】
第十一章 单元测试
1、多选题:
关于L1正则和L2正则 下面的说法正确的是( )
选项:
A:L2正则化有个名称叫“Lasso regularization”
B:L2正则化表示各个参数的平方和的开方值
C:L2范数可以防止过拟合,提升模型的泛化能力。但L1正则做不到这一点
D:L1范数会使权值稀疏
答案: 【】
2、单选题:
关于特征选择,下列对 Ridge 回归和 Lasso 回归说法正确的是?( )
选项:
A:选项中说法都不对
B:Ridge 回归适用于特征选择
C:两个都适用于特征选择
D:Lasso 回归适用于特征选择
答案: 【】
3、单选题:
下列哪一种方法的系数没有闭式(closed-form)解?( )
选项:
A:Ridge 回归
B:Lasso
C:选项中都不是
D:Ridge 回归和 Lasso
答案: 【
4、多选题:
我们希望减少数据集中的特征数量。你可以采取以下哪一个步骤来减少特征?( )
选项:
A:逐步选择消除法(Stepwise)
B:使用正向选择法(Forward Selection)
C:使用反向消除法(Backward Elimination)
D:计算不同特征之间的相关系数,删去相关系数高的特征之一
答案: 【
5、多选题:
建立线性模型时,我们看变量之间的相关性。在寻找相关矩阵中的相关系数时,如果发现 3 对变量(Var1 和 Var2、Var2 和 Var3、Var3 和 Var1)之间的相关性分别为 -0.98、0.45 和 1.23。我们能从中推断出什么呢?( )
选项:
A:Var1 和 Var2 存在多重共线性,模型可以去掉其中一个特征
B:Var1 和 Var2 具有很高的相关性
C:选项中说法都不对
D:Var3 和 Var1 相关系数为 1.23 是不可能的
答案: 【】


评论0