第一章 单元测试
1、多选题:
下列属于多元统计方法的为( )
选项:
A:决策树
B:主元分析
C:回归分析
D:神经网络
答案: 【主元分析
;回归分析
】
2、多选题:
多元统计分析的图表示法有( )
选项:
A:轮廓图
B:雷达图
C:调和曲线图
D:散布图矩阵
答案: 【轮廓图
;雷达图
;调和曲线图
;散布图矩阵
】
3、判断题:
完整的数据分析过程,包括数据采集、数据清洗和数据分析。( )
选项:
A:对
B:错
答案: 【对】
4、单选题:
下列场景适用于回归分析的是 ( )
选项:
A:天气预报
B:水果分拣
C:信息浓缩
D:人脸识别
答案: 【天气预报
】
5、单选题:
下面哪一句体现了主元分析的思想( )
选项:
A:物以类聚,人以群分
B:笨鸟先飞
C:牵牛要牵牛鼻子
D:人不是一座孤岛
答案: 【牵牛要牵牛鼻子
】
第二章 单元测试
1、多选题:
一般常见的缺失值处理的方法有( )
选项:
A:替换填充法
B:插值填充
C:回归填充法
D:最近邻插补填充法
答案: 【替换填充法
;插值填充
;回归填充法
;最近邻插补填充法
】
2、多选题:
一般常见的数据归一化的方法有( )
选项:
A:最小最大规范化
B:回归填充法
C:替换填充法
D:零均值规范化
答案: 【最小最大规范化
;零均值规范化
】
3、判断题:
少量的异常值完全不会影响数据分析。( )
选项:
A:对
B:错
答案: 【错】
4、单选题:
下列哪种方法不是数据填补的手段 ( )
选项:
A:均值标准化
B:插值填充法
C:替换填充法
D:回归填充法
答案: 【均值标准化
】
5、单选题:
主成分分析的英文名是( )。
选项:
A:Principal Component Analysis
B:Ordinary Least Squares
C:Partial Least Squares
D:Canonical Component Analysis
答案: 【Principal Component Analysis
】
第三章 单元测试
1、多选题:
下面哪个是SVM在实际生活中的应用( )
选项:
A:图片分类
B:邮件分类
C:文本翻译
D:房价预测
答案:
2、多选题:
以下说法正确的有哪些( )
选项:
A:核方法不能解决非线性问题
B:软间隔的引入可以解决轻度线性不可分问题
C:SVM只能够解决回归问题
D:SVM是一种线性方法
答案:
3、判断题:
拉格朗日乘子法可用于线性可分SVM的模型求解。( )
选项:
A:错
B:对
答案:
4、单选题:
SVM的中文全称叫什么?( )
选项:
A:支持向量机
B:最小向量分类器
C:支持向量回归器
D:最大向量分类器
答案:
5、单选题:
SVM算法的最小时间复杂度是O(n²),基于此,以下哪种规格的数据集并不适该算法?( )
选项:
A:不受数据集的大小影响
B:小数据集
C:中等数据集
D:大数据集
答案:
第四章 单元测试
1、多选题:
一元线性回归有哪些基本假定?( )
选项:
A:随机误差项和解释变量X不相关;
B:随机误差项具有零均值、同方差和序列不相关的性质;
C:随机误差项服从零均值、同方差的正态分布。
D:解释变量X是确定性变量,Y是随机变量;
答案:
2、多选题:
最典型的两种拟合不佳的情况是( )。
选项:
A:强拟合
B:欠拟合
C:弱拟合
D:过拟合
答案:
3、判断题:
岭回归适用于样本很少,但变量很多的回归问题。( )
选项:
A:错
B:对
答案:
4、单选题:
最小二乘方法的拟合程度衡量指标是( )。
选项:
A:残差和
B:均值差
C:残差平方和
D:拟合残差
答案:
5、单选题:
关于最小二乘法,下列说法正确的是。( )
选项:
A:最小二乘法要求样本点到拟合直线的竖直距离的平方和最小
B:最小二乘法要求样本点到拟合直线的垂直距离的和最小
C:最小二乘法要求样本点到拟合直线的垂直距离的平方和最小
D:最小二乘法要求样本点到拟合直线的竖直距离的和最小
答案:
第五章 单元测试
1、判断题:
在区分某个算法是否是聚类算法时,往往可以通过该算法是否需要预先设定明确的类中心来判断( )。
选项:
A:对
B:错
答案:
2、多选题:
闵可夫斯基距离是一组距离的定义,下列距离中属于闵可夫斯基距离的有( )
选项:
A:欧式距离
B:曼哈顿距离
C:马氏距离
D:切比雪夫距离
答案:
3、多选题:
在利用EM算法估计高斯混合模型参数的时候,需要预先设定的参数有( )。
选项:
A:高斯元的方差
B:类别个数
C:高斯元的均值
D:高斯元的权重系数
答案:
4、单选题:
聚类算法是一种( )的学习方式。
选项:
A:无监督
B:有监督
C:自上而下
D:Q型
答案:
5、单选题:
理想情况下,K均值算法中确定类别个数的最佳方式为( )。
选项:
A:无需提前确定,可以在训练中得到
B:随机确定
C:结合先验知识确定
D:根据比较不同类别个数时的聚类效果来确定
答案:
第六章 单元测试
1、判断题:
随机森林只能选择决策树作为基分类器。( )
选项:
A:对
B:错
答案:
2、单选题:
在Bootstrap自助采样法中,真实的情况是( )。
选项:
A:在每一次采样中,样本之间不重复;在完成n次采样之后,有些样本可能没有被采集到
B:在每一次采样中,样本之间不重复;在完成n次采样之后,所有样本都会被采集到
C:在每一次采样中,样本之间可能有重复;在完成n次采样之后,有些样本可能没有被采集到
D:在每一次采样中,样本之间可能有重复;在完成n次采样之后,所有样本都会被采集到
答案:
3、单选题:
对于离散型随机变量X,它的熵取决于( )。
选项:
A:X的期望
B:X的分布函数
C:X取每个值的概率
D:X的取值范围
答案:
4、多选题:
随机森林有哪些优点( )。
选项:
A:减弱单决策树的过拟合情况
B:训练速度快
C:可以给出特征的重要性大小
D:可以处理高维度数据
答案:
5、多选题:
随机森林的随机性体现在哪里( )
选项:
A:每棵树的结点采用随机属性搜索
B:随机采用随机抽取的样本来训练整个随机森林
C:每棵树采用随机取样训练
D:随机删除一些树内结点
答案:
第七章 单元测试
1、判断题:
典型相关分析适用于分析两组变量之间的关系( )
选项:
A:错
B:对
答案:
2、单选题:
CCA算法在求解时,分别在两组变量中选取具有代表性的综合变量Ui,Vi,每个综合变量是原变量的线性组合,选择综合变量时的目标是( )
选项:
A:最大化两者的相关系数
B:最小化两者的距离
C:最大化两者的距离
D:最小化两者的相关系数
答案:
3、单选题:
相比于普通CCA算法,Kernel CCA( )
选项:
A:能分析两组随机变量之间的非线性关系
B:将标签信息融入到CCA框架中
C:只考虑临近点的影响
D:使用了自编码器
答案:
4、多选题:
关于典型相关分析CCA与主成分分析PCA,下面说法错误的是( )
选项:
A:考虑了变量的相关性信息
B:PCA可以视为一种降维技术,CCA不可以视为一种降维技术
C:都基于变量的线性变换
D:是否进行归一化,都不影响分析结果
答案:
5、多选题:
传统典型相关分析的基本假设包括( )
选项:
A:样本的同质性高,但各组内变量间不能有高度的复共线性。
B:两组变量的地位是相等的。
C:变量间的关系是线性关系:每对典型变量之间是线性关系,每个典型变量与本组变量之间也是线性关系;
D:变量具有正态性;
答案:
第八章 单元测试
1、判断题:
为了提高预测结果的精度,网络结构设置得越复杂越好,不必考虑训练网络时所花费的时间。( )
选项:
A:对
B:错
答案:
2、单选题:
下面哪个函数不是神经元的激活函数( )
选项:
A: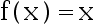
B: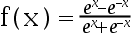
C: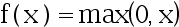
D: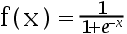
答案:
3、单选题:
关于卷积神经网络CNN,以下说法错误的是:( )
选项:
A:由于卷积核的大小一般是3*3或更大,因此卷积层得到的特征图像一定比原图像小。
B:CNN中的全连接层常用softmax作为激活函数。
C:CNN中的池化层用于降低特征图维数,以避免过拟合。
D:CNN由卷积层、池化层和全连接层组成,常用于处理与图像有关的问题。
答案:
4、多选题:
相较于传统RNN,LSTM引入了独特的门控机制。以下哪些是LSTM中包含的门结构:( )
选项:
A:遗忘门
B:更新门
C:输出门
D:输入门
答案:
5、多选题:
关于卷积神经网络CNN与循环神经网络RNN,下面说法正确的有:( )
选项:
A:在同一个网络中,CNN结构和RNN结构不能同时使用。
B:CNN适用于图像处理,而RNN适用于序列数据处理。
C:CNN和RNN都属于神经网络,因此二者的训练方式完全一致,均采用BP算法。
D:CNN和RNN都采用了权值共享机制以减少网络中的参数量。
答案:
第九章 单元测试
1、判断题:
自编码器的训练属于半监督学习。( )
选项:
A:对
B:错
答案:
2、单选题:
下面哪一种算法属于生成式模型( )。
选项:
A:变分自编码器
B:支持向量机
C:决策树
D:线性回归模型
答案:
3、单选题:
关于去噪自编码器DAE,以下说法错误的是:( )
选项:
A:DAE一般以含噪声数据作为输入,并输出重构的去噪数据。
B:DAE训练时需要保证训练数据的完整性。
C:DAE中假设所有含噪样本的损坏过程一致。
D:DAE的Loss函数用于最小化预测结果 与噪声数据 间的误差。
答案:
4、多选题:
在稀疏自编码器中,假设神经元采用tanh作为激活函数,则:( )
选项:
A:当神经元的输出接近-1的时候,认为它被抑制。
B:当神经元的输出接近1的时候,认为它被激活。
C:当神经元的输出接近0的时候,认为它被抑制。
D:当神经元的输出接近0的时候,认为它被激活。
答案:
5、多选题:
关于变分自编码器VAE,以下说法正确的有:( )
选项:
A:VAE是一类生成模型,可用于训练出一个样本的生成器。
B:VAE的变分下界由KL散度项和模型重建误差项组成。
C:VAE广泛用于生成图像。
D:VAE的变分下界中,KL散度项可以为负值。
答案:
第十章 单元测试
1、判断题:
一般情况下我们在模型训练及调参前要先进行数据分析预处理以及特征工程,这是十分必要的一环( )。
选项:
A:错
B:对
答案:
2、多选题:
对于糖尿病的血糖预测,我们可以考虑使用( )方法。
选项:
A:LSTM
B:SVM
C:DNN
D:SVR
答案:
3、单选题:
工业蒸汽量预测是一个( )问题。
选项:
A:聚类
B:二分类
C:自回归
D:多元回归
答案:
4、单选题:
DBDAE降噪,训练过程中停止训练是因为( )。
选项:
A:节省训练时间
B:防止进一步学习噪声的信息
C:训练的Loss已经达到最小值
D:PCA的重构误差已经最小
答案:
5、多选题:
双盲降噪自编码器中的“双盲”是指( )。
选项:
A:无需得知噪声的特征信息
B:无需训练至Loss最小
C:无需了解信号的纯净版本
D:无需训练中加入范数约束
答案:


请先 !